Concept of BM25 Vectors

Note: If you are landing here directly, then it is suggested that you first have a look at this link : https://adityagoel123.medium.com/concept-of-tf-idf-vectors-65774b908a93
Question → What is BM-25 Method ?
Answer → BM-25 is actually an improved version of TF-IDF, but still this is also yet another Sparse Vector Methods, which essentially means that , they are vectors where there are lots of Zeros with occasional value in there.
Question → How do we compute the BM-25 Score ?
Answer → Here, is how we compute the BM25 Score for a given query in any given document :-

Following are the meanings of the various terms :-
- q → Stands for Query.
- f(q, D) → What is the frequency of query “q” in document “D”.
- f(t, D) → What is the frequency of all terms “t” in our document “D” → Total number of Terms in the document.
- D → Stands for current Document length.
- davg → (Length of all the documents) / (No. of Documents).
- N → Total number of documents.
- N (q) → Total number of documents that contains the query “q” into them.
- k → Usualy a constant with value of 1.25.
- k → Usualy a constant with value of 0.75.
Question → Can you showcase the computation of BM-25 Score using Python3 ?
Answer → Below is the Python based score computation approach :-
1.) Here is how our all the documents looks like :-

2.) Now, we form our docs array :-

3.) Just as a recap, here is how our TF*IDF computation looks like :-

4.) Below is how our BM-25 score is calculated :-

5.) Below are some sample invocations of this method :-
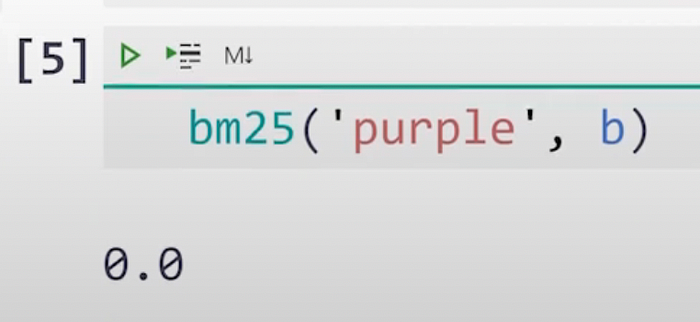
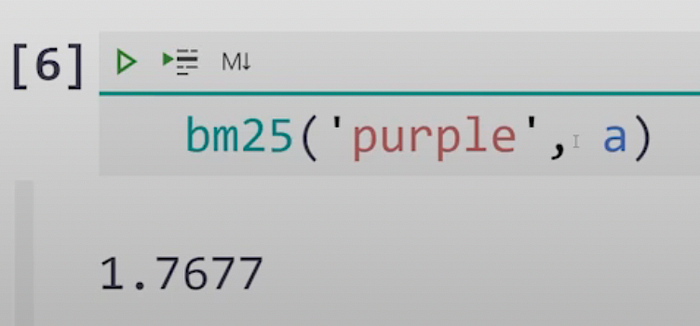
6.) Here is yet another example-demonstration of this method :-
Question → What are the differences between the TF*IDF method and BM-25 method ?
Answer → Below is the major difference in the working of both of these methods :-
- The score of (TF*IDF) increases linearly with the increasing frequency for the number of words OR number of matching terms, whereas the score of BM25 increases a lot quickly and then it kind of levels-off.
- Thus, if there are eight words in the document matching to the query, then it would be slightly more relevant as compared to the document which contains 4 words matching to the query AND not that much.
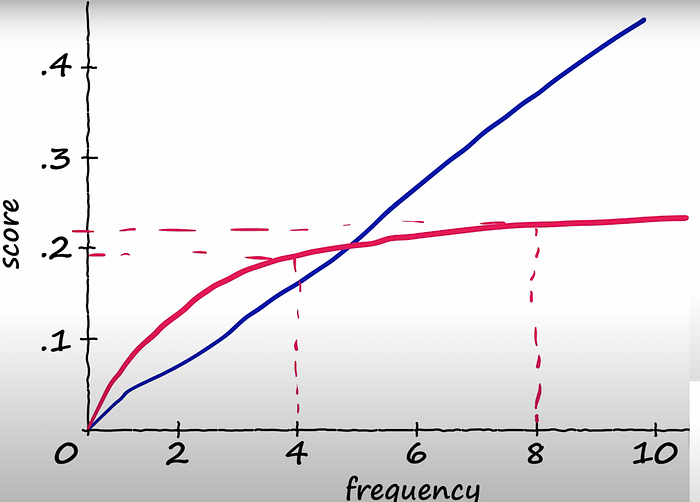
Therefore, from my experience in most of the cases, the BM25 Score is more realistic.
In next blog, we shall see about another method known as sBERT. SBERT is an example of dense-vector. Dense-Vectors are quite interesting as they allow us to consider semantics.