Concept of TF*IDF Vectors

Question → Explain the concept of TF-IDF ?
Answer → TF-IDF is a Sparse-Vector method, where there are lots of Zeros with occasional value in there.
1.) TF stands for Term-Frequency. It looks at a sentence OR a paragraph and given a certain query, it will tell you → Compared to the length of that document, how frequent your query is ?
- q → Stands for Query.
- D → Stands for Document.
- f(q, D) → What is the frequency of query “q” in document “D”.
- f(t, D) → What is the frequency of all terms “t” in our document “D” → Total number of Terms in the document.

2.) IDF stands for Inverse-Document-Frequency. It is calculated for each document. Document here means either a Sentence OR a paragraph. In below example, we have 3 different documents.

- N → Total number of documents.
- N (q = ‘is’) → Total number of documents that contains the query “is” into them.
3.) Let’s see some couple of calculations here for TF*IDF :-

Notes :-
==> There are chances that, “Most common words” are not that highly relevant to our query.
==> There are chances that, “Less common words” are more relevant to our query.
4.) Now, we see the entire calculations here :-

Question → Showcase the TF-IDF in Python ?
Step #1.) Here is how our set of 3 documents looks like :-

Step #2.) Next, this is how, we can compute the term : [TF * IDF] :-
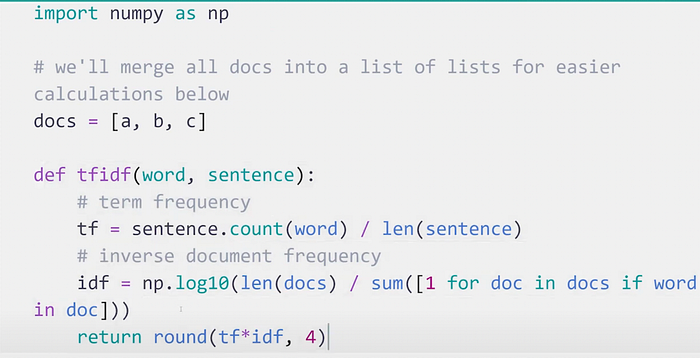
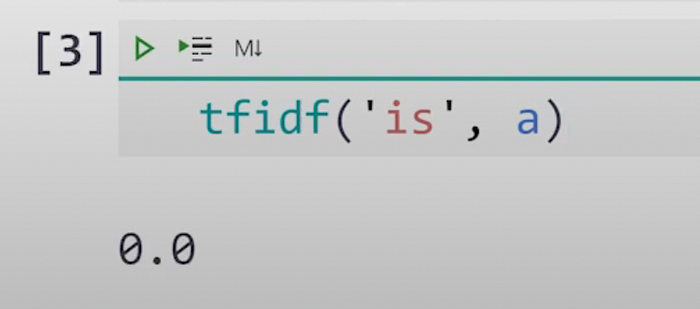
Step #3.1) Now let’s check the value of [TF * IDF] for this term :-
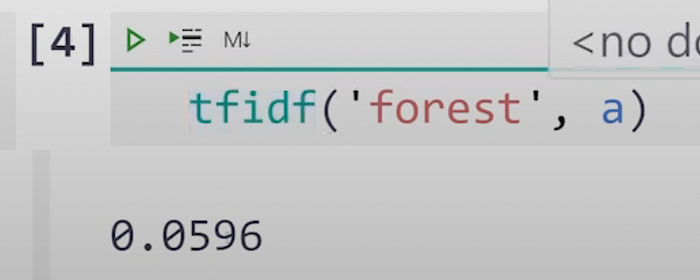
Step #3.2) Let’s also check the value of [TF * IDF] for another term :-
Question → TF-IDF are sparse vectors, but obviously whatever we have done above, doesn’t looks much like a vector. So, how do we turn them into the vectors ?
Step #1.) Let’s build the vocabulary :-

Step #2.) Now, we shall take this Vocab and mirror it into a vector, so that for every word, we are going to calculate the TF*IDF for each document.
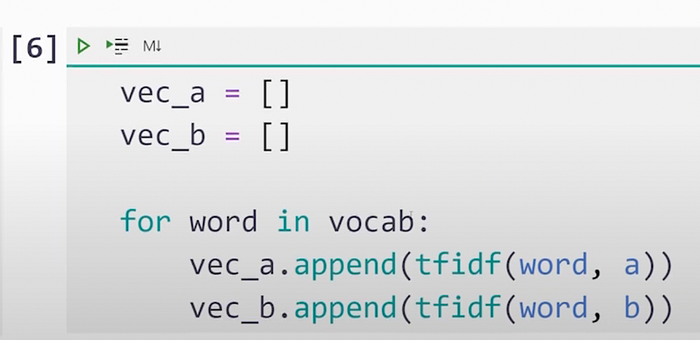
And here is the vector that we get for “a” :-

And here is the vector that we get for “b” :-

Question → What’s the disadvantage of (TF * IDF) ?
Answer → If the frequency of queries found in a document increases, the score increases linearly. For example →
- Imagine we have an 1000–word-document (document-1) and it has the word “dog” 10 times → There is a good chance that, document is talking about the dogs, right !! Also, there shall be some score == TF*IDF(“dog”, document-1)
- Now, if number of times the word “dog” appears in another document (document-2) say is 20, then TF*IDF(“dog”, document-2) score for that document shall also double, because the TF*IDF score is directly proportional to the Term-Frequency of word “dog”.
Now, it doesn’t mean that document-2 is more relevant as compared to the document-1, in context of query “dog”. Rather, it may so happen that, the document-2 is just slightly relevant as compared to the document-1. Therefore, in order to address this problem, comes BM25, which we shall discuss in next blog.