aditya goelDeep dive into AWS for developers | Part7 — SageMakerIn case, you are landing here directly, it would be recommended to visit the previous blogs of this series, but this particular blog is…14 min read·Mar 12, 2024----
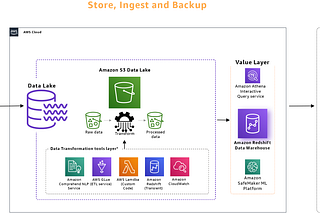
aditya goelDeep dive into AWS for developers | Part6 — DataLakeIn case, you are landing here directly, it would be recommended to visit this page.10 min read·Mar 9, 2024----
aditya goelDeep dive into AWS for developers | Part5 — DataLakeIn case, you are landing here directly, it would be recommended to visit this page.6 min read·Mar 6, 2024----
aditya goelDeep Dive into Apache Spark || Part-2If you are landing here directly, it’s strongly advisable to read through this blog first.7 min read·Mar 5, 2024----
aditya goelSentiment Classification in NLP | Part-3 | Vector Space ModelsIf you are landing at this page directly, it’s advisable that you go through this page first.11 min read·Mar 1, 2024----
aditya goelDeep dive into Spark || Part-1Question → What’s so special about the Spark ?13 min read·Mar 1, 2024----
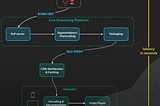
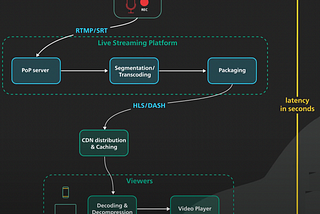
aditya goelLive Streaming System Design || Part2If you are landing here directly, please go through this Part-1 blog first.9 min read·Feb 29, 2024----
aditya goelDeep dive || Aerospike FundamentalsQuestion → What is a Node in Aerospike setup ?11 min read·Feb 27, 2024----
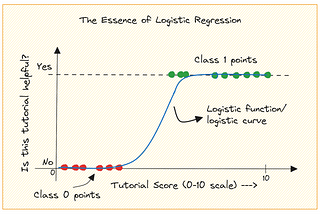
aditya goelSentiment Classification in NLP | Part-2 | Logistic RegressionIf you are landing here directly, it may be good to read through this blog first.10 min read·Feb 20, 2024----